最近一直在学习大语言模型,一直在尝试解决一个实现如何能把自然语言转换成数据库的查询语句的问题。下面的这个尝试是一个非常有趣的实验,最终还得到了不错的结果,准确率达到了94%以上!
下面请跟着我一起来一步一步的做吧,不过在这之前,要使实验能够顺利进行,请准备好科学上网,否则有些要去Huggingface下载模型的地方会出错。
OK,let’s GO~!
首先,导入必要的包。
scikit-learn==1.5.0
transformers==4.41.2
pandas==2.2.2
numpy==1.26.4
datasets==2.20.0
evaluate==0.4.2
torch==2.3.1+cu121
torchaudio==2.3.1+cu121
torchvision==0.18.1+cu121
--index-url https://download.pytorch.org/whl/cu121
accelerate==0.31.0
rouge_score==0.1.2from sklearn.model_selection import train_test_split
from datasets import Dataset, DatasetDict, load_dataset, interleave_datasets, load_from_disk
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig, TrainingArguments, Trainer
import torch
import time
import evaluate
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
# 检查torch是否正确安装
torch.cuda.is_available()
# 返回True标明torch安装成功然后,让我们把我们依赖的模型T5 small加载进来,这个模型非常小,只有200多M的大小,一般的电脑都能够使用得了。
model_name='t5-small'
tokenizer = AutoTokenizer.from_pretrained(model_name)
original_model = AutoModelForSeq2SeqLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16
)
original_model = original_model.to('cuda')然后,下面的3个Huggingface的链接是我们要用的3个数据集,我们使用这三个数据集来作为我们的训练数据。
- https://huggingface.co/datasets/b-mc2/sql-create-context
- https://huggingface.co/datasets/Clinton/Text-to-sql-v1
- https://huggingface.co/datasets/knowrohit07/know_sql
由于这是3个不同的数据集,所以我们要对数据集做统一处理成相同的数据列名和格式,方便后面做数据集分割。
try:
dataset = load_from_disk("merged_dataset")
print("Loaded Merged Dataset")
except:
dataset_scc_train = load_dataset("b-mc2/sql-create-context", split='train[:80%]')
dataset_scc_test = load_dataset("b-mc2/sql-create-context", split='train[-20%:-10%]')
dataset_scc_val = load_dataset("b-mc2/sql-create-context", split='train[-10%:]')
dataset_tts_train = load_dataset("Clinton/Text-to-sql-v1", split='train[:80%]')
dataset_tts_train = dataset_tts_train.remove_columns(['source', 'text'])
dataset_tts_train = dataset_tts_train.rename_columns({'instruction': 'question', 'input': 'context', 'response': 'answer'})
dataset_tts_test = load_dataset("Clinton/Text-to-sql-v1", split='train[-20%:-10%]')
dataset_tts_test = dataset_tts_test.remove_columns(['source', 'text'])
dataset_tts_test = dataset_tts_test.rename_columns({'instruction': 'question', 'input': 'context', 'response': 'answer'})
dataset_tts_val = load_dataset("Clinton/Text-to-sql-v1", split='train[-10%:]')
dataset_tts_val = dataset_tts_val.remove_columns(['source', 'text'])
dataset_tts_val = dataset_tts_val.rename_columns({'instruction': 'question', 'input': 'context', 'response': 'answer'})
dataset_ks_train = load_dataset("knowrohit07/know_sql", split='validation[:80%]')
dataset_ks_test = load_dataset("knowrohit07/know_sql", split='validation[-20%:-10%]')
dataset_ks_val = load_dataset("knowrohit07/know_sql", split='validation[-10%:]')
dataset = DatasetDict({ 'train': interleave_datasets([dataset_scc_train, dataset_tts_train, dataset_ks_train]),
'test': interleave_datasets([dataset_scc_test, dataset_tts_test, dataset_ks_test]),
'validation': interleave_datasets([dataset_scc_val, dataset_tts_val, dataset_ks_val])})
dataset.save_to_disk("merged_dataset")
print("Merged and Saved Dataset")
# dataset让我们快速看看数据集是否OK。
dataset['test'][0]数据集返回了以下内容表明数据集已经处理成功。
{‘answer’: ‘SELECT date FROM table_name_11 WHERE away_team = “essendon”‘, ‘question’: ‘On what Date did the Away team essendon play?’, ‘context’: ‘CREATE TABLE table_name_11 (date VARCHAR, away_team VARCHAR)’}
我们看到返回测试集的第一条数据,包含question、context和answer字段的数据。下面我们给我们的数据打标记(Tokenize)
def tokenize_function(example):
start_prompt = "Tables:\n"
middle_prompt = "\n\nQuestion:\n"
end_prompt = "\n\nAnswer:\n"
data_zip = zip(example['context'], example['question'])
prompt = [start_prompt + context + middle_prompt + question + end_prompt for context, question in data_zip]
example['input_ids'] = tokenizer(prompt, padding="max_length", truncation=True, return_tensors="pt").input_ids
example['labels'] = tokenizer(example['answer'], padding="max_length", truncation=True, return_tensors="pt").input_ids
return example
# 这个数据集包含3个不同的部分: train, validation, test.
tokenized_datasets = dataset.map(tokenize_function, batched=True)
tokenized_datasets = tokenized_datasets.remove_columns(['question', 'context', 'answer'])打印一下处理的结果:
print(tokenized_datasets.keys())
print(tokenized_datasets['train'][0].keys())
print(tokenized_datasets['train'][0]['input_ids'][:10])
print(tokenized_datasets['train'][0]['labels'][:10])
print(tokenized_datasets)dict_keys([‘train’, ‘test’, ‘validation’])
dict_keys([‘input_ids’, ‘labels’])
[4398, 7, 10, 205, 4386, 6048, 332, 17098, 819, 41] [3, 23143, 14196, 2847, 17161, 599, 1935, 61, 21680, 819]
DatasetDict({
train: Dataset({
features: [‘input_ids’, ‘labels’],
num_rows: 118695
})
test: Dataset({
features: [‘input_ids’, ‘labels’],
num_rows: 14835
})
validation: Dataset({
features: [‘input_ids’, ‘labels’],
num_rows: 14838
})
})
从上面的结果看,可以看到我们已经把整个数据集划分成了训练集(train)、测试集(test)和验证集(validation),而且每个集和所包含的数据数量。
在开始微调之前,我们先简单测试一下微调之前的模型的表现。我们从数据集中抽取一条数据,看看他是否能根据条件生成对应的sql语句。
index = 0
question = dataset['test'][index]['question']
context = dataset['test'][index]['context']
answer = dataset['test'][index]['answer']
prompt = f"""Tables:
{context}
Question:
{question}
Answer:
"""
inputs = tokenizer(prompt, return_tensors='pt')
inputs = inputs.to('cuda')
output = tokenizer.decode(
original_model.generate(
inputs["input_ids"],
max_new_tokens=200,
)[0],
skip_special_tokens=True
)
dash_line = '-'.join('' for x in range(100))
print(dash_line)
print(f'INPUT PROMPT:\n{prompt}')
print(dash_line)
print(f'BASELINE HUMAN ANSWER:\n{answer}\n')
print(dash_line)
print(f'MODEL GENERATION - ZERO SHOT:\n{output}')上面的代码,我们取第1条(Index=0,你可以自己换其他的记录来做测试),创建一个简单的prompt,并把context和question一起提供给T5模型,下面是执行之后的结果:
—————————————————————————————————
INPUT PROMPT:
Tables: CREATE TABLE table_name_11 (date VARCHAR, away_team VARCHAR)
Question:
On what Date did the Away team essendon play?
Answer:
—————————————————————————————————
BASELINE HUMAN ANSWER: SELECT date FROM table_name_11 WHERE away_team = “essendon”
—————————————————————————————————
MODEL GENERATION – ZERO SHOT:
Question
嗯,看起来模型表现得不理想,模型返回的结果是字符串“Question”,这明显不符合要求,我们需要的是对应的sql语句。
那我们看看使用了上面的数据集对模型做微调之后看看是否得到我们想要的结果。那我们正式开始微调把。
我们创建一个新的变量finetuned_model来保存这个模型,首先要把基础模型T5 small导入。
finetuned_model = AutoModelForSeq2SeqLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
finetuned_model = finetuned_model.to('cuda')
tokenizer = AutoTokenizer.from_pretrained(model_name)接下来我们使用Huggingface trainer工具来做模型的训练,这里我使用的超参是 2 epochs, 学习率:5e-3, 和 batch size 16,你也可以尝试去调整一下这些参数的值,看看是否有更好的结果。
output_dir = f'./sql-training-{str(int(time.time()))}'
training_args = TrainingArguments(
output_dir=output_dir,
learning_rate=5e-3,
num_train_epochs=2,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
weight_decay=0.01,
logging_steps=50,
evaluation_strategy='steps',
eval_steps=500,
)
trainer = Trainer(
model=finetuned_model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['validation'],
)
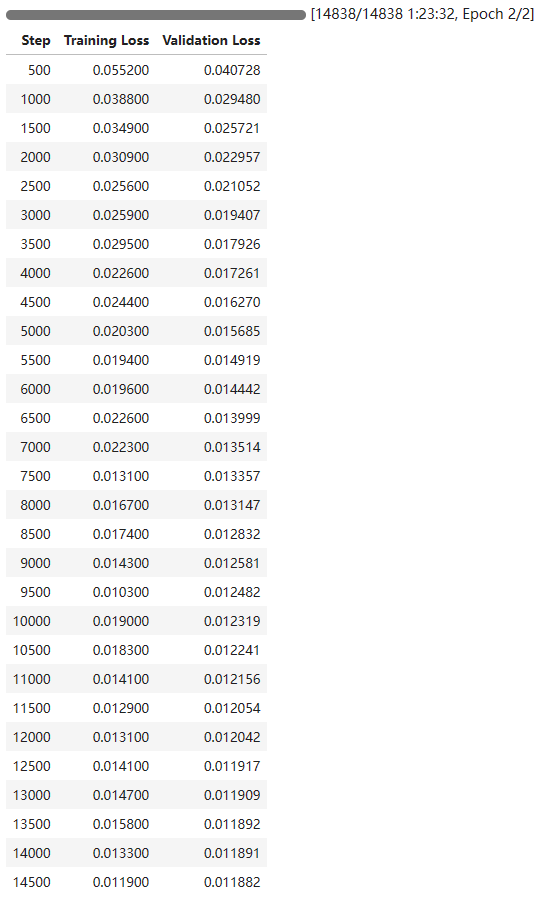
trainer.train()我使用的是RTX 3090消费性显卡,这个训练的过程大概花了我1个半小时。结果如下,看起来还不错。
我们先把训练好的模型保存到本地磁盘,后面便可以直接导入它来使用了。
finetuned_model.save_pretrained("finetuned_model_2_epoch")下面我们把训练好的模型导进来做一下测试看看效果如何
finetuned_model = AutoModelForSeq2SeqLM.from_pretrained("finetuned_model_2_epoch")
finetuned_model = finetuned_model.to('cuda')index = 0
# index = len(dataset['test'])-200
question = dataset['test'][index]['question']
context = dataset['test'][index]['context']
answer = dataset['test'][index]['answer']
prompt = f"""Tables:
{context}
Question:
{question}
Answer:
"""
inputs = tokenizer(prompt, return_tensors='pt')
inputs = inputs.to('cuda')
output = tokenizer.decode(
finetuned_model.generate(
inputs["input_ids"],
max_new_tokens=200,
)[0],
skip_special_tokens=True
)
dash_line = '-'.join('' for x in range(100))
print(dash_line)
print(f'INPUT PROMPT:\n{prompt}')
print(dash_line)
print(f'BASELINE HUMAN ANSWER:\n{answer}\n')
print(dash_line)
print(f'FINE-TUNED MODEL - ZERO SHOT:\n{output}')很明显这个开卷考试对它来说毫无压力,得到的结果也是我们想要的。
---------------------------------------------------------------------------------------------------
INPUT PROMPT:
Tables:
CREATE TABLE table_name_11 (date VARCHAR, away_team VARCHAR)
Question:
On what Date did the Away team essendon play?
Answer:
---------------------------------------------------------------------------------------------------
BASELINE HUMAN ANSWER:
SELECT date FROM table_name_11 WHERE away_team = "essendon"
---------------------------------------------------------------------------------------------------
FINE-TUNED MODEL - ZERO SHOT:
SELECT date FROM table_name_11 WHERE away_team = "essendon"
那我们用一些复杂一点的例子,看看它的表现如何:
我改了一下上面的index的值为 len(dataset[“test]_ – 200,也就是倒数第200条数据。下面是运行的结果。
—————————————————————————————————
INPUT PROMPT:
Tables:
CREATE TABLE employees (
EMPLOYEE_ID decimal(6,0),
FIRST_NAME varchar(20),
LAST_NAME varchar(25),
EMAIL varchar(25),
PHONE_NUMBER varchar(20),
HIRE_DATE date,
JOB_ID varchar(10),
SALARY decimal(8,2),
COMMISSION_PCT decimal(2,2),
MANAGER_ID decimal(6,0),
DEPARTMENT_ID decimal(4,0)
)
CREATE TABLE jobs (
JOB_ID varchar(10),
JOB_TITLE varchar(35),
MIN_SALARY decimal(6,0),
MAX_SALARY decimal(6,0)
)
CREATE TABLE locations (
LOCATION_ID decimal(4,0),
STREET_ADDRESS varchar(40),
POSTAL_CODE varchar(12),
CITY varchar(30),
STATE_PROVINCE varchar(25),
COUNTRY_ID varchar(2)
)
CREATE TABLE countries (
COUNTRY_ID varchar(2),
COUNTRY_NAME varchar(40),
REGION_ID decimal(10,0)
)
CREATE TABLE job_history (
EMPLOYEE_ID decimal(6,0),
START_DATE date,
END_DATE date,
JOB_ID varchar(10),
DEPARTMENT_ID decimal(4,0)
)
CREATE TABLE regions (
REGION_ID decimal(5,0),
REGION_NAME varchar(25)
)
CREATE TABLE departments (
DEPARTMENT_ID decimal(4,0),
DEPARTMENT_NAME varchar(30),
MANAGER_ID decimal(6,0),
LOCATION_ID decimal(4,0)
)
Question:
For those employees who did not have any job in the past, give me the comparison about the amount of job_id over the job_id , and group by attribute job_id, and list from low to high by the JOB_ID please.
Answer:
—————————————————————————————————
BASELINE HUMAN ANSWER:
SELECT JOB_ID, COUNT(JOB_ID) FROM employees WHERE NOT EMPLOYEE_ID IN (SELECT EMPLOYEE_ID FROM job_history) GROUP BY JOB_ID ORDER BY JOB_ID
—————————————————————————————————
FINE-TUNED MODEL – ZERO SHOT:
SELECT JOB_ID, COUNT(JOB_ID) FROM employees WHERE NOT EMPLOYEE_ID IN (SELECT EMPLOYEE_ID FROM job_history) GROUP BY JOB_ID ORDER BY JOB_ID
嗯,看起来效果还不错。这是一个多表连表查询的例子,他能正确地推断出了结果。太棒了!
我们继续使用ROUGE方法来对结果做一个更正式的对比,看看微调模型在微调之前和微调之后的差别。
rouge = evaluate.load('rouge')
original_model_results = rouge.compute(
predictions=original_model_answers,
references=human_baseline_answers[0:len(original_model_answers)],
use_aggregator=True,
use_stemmer=True,
)
print('微调前:')
print(original_model_results)
finetuned_model_results = rouge.compute(
predictions=finetuned_model_answers,
references=human_baseline_answers[0:len(finetuned_model_answers)],
use_aggregator=True,
use_stemmer=True,
)
print('微调后:')
print(finetuned_model_results)运行的结果如下:
微调前:
{‘rouge1’: 0.21704322055672515, ‘rouge2’: 0.08948525438138659, ‘rougeL’: 0.2045947778424302, ‘rougeLsum’: 0.20537011782972064}
微调后:
{‘rouge1’: 0.9489591365202867, ‘rouge2’: 0.9244602974758165, ‘rougeL’: 0.9429229831741407, ‘rougeLsum’: 0.9431012984672789}
结果非常nice,正确率已经达到了94.89%!
这个虽然看起来非常的激动,由于训练的语料库都是英文的,对中文的支持并不太理想,我后面会想办法创建一些中文的训练数据,重新对这个模型做训练,期待能更好的适应国内的一些场景。
:)